AI Speech Emotion Recognition
AI-driven speech emotion recognition.
- Service
-
AI Development
Services
- Industry
- IT & Software Services
Challenge
A healthy psychological climate in a team and a friendly environment provide an effective work process and help achieve significant results in any industry. Today, companies pay great attention to employees’ mental health due to possible consequences, such as burnout, and make it a part of digital transformation to build a cohesive team.
According to the findings of the World Health Organization, “depression is a leading cause of disability worldwide and is a major contributor to the overall global burden of disease.” In the 2022 world’s ever-accelerating changes, pandemic, and difficult geopolitical situation, the disease prevalence even rose by 25%; that’s why mental health issue deserves particular attention today.
So, a modern world requires modern solutions. Sometimes managers could be swamped with an enormous amount of work and cannot pay enough attention to the mental health of their colleagues. So, it could lead to misunderstandings, hidden conflicts, and a decrease in the overall work performance of the team. This way, machine learning automation of emotion detection could be a good solution for reasonable delegation.
Hypothesis
A lot of communication in the workplace is based on sharing thoughts via voice conversation. For this reason, we turned to the Computer Vision field, providing an opportunity for automatic emotion recognition from speech using machine learning to help managers and team members create reliable cooperation.
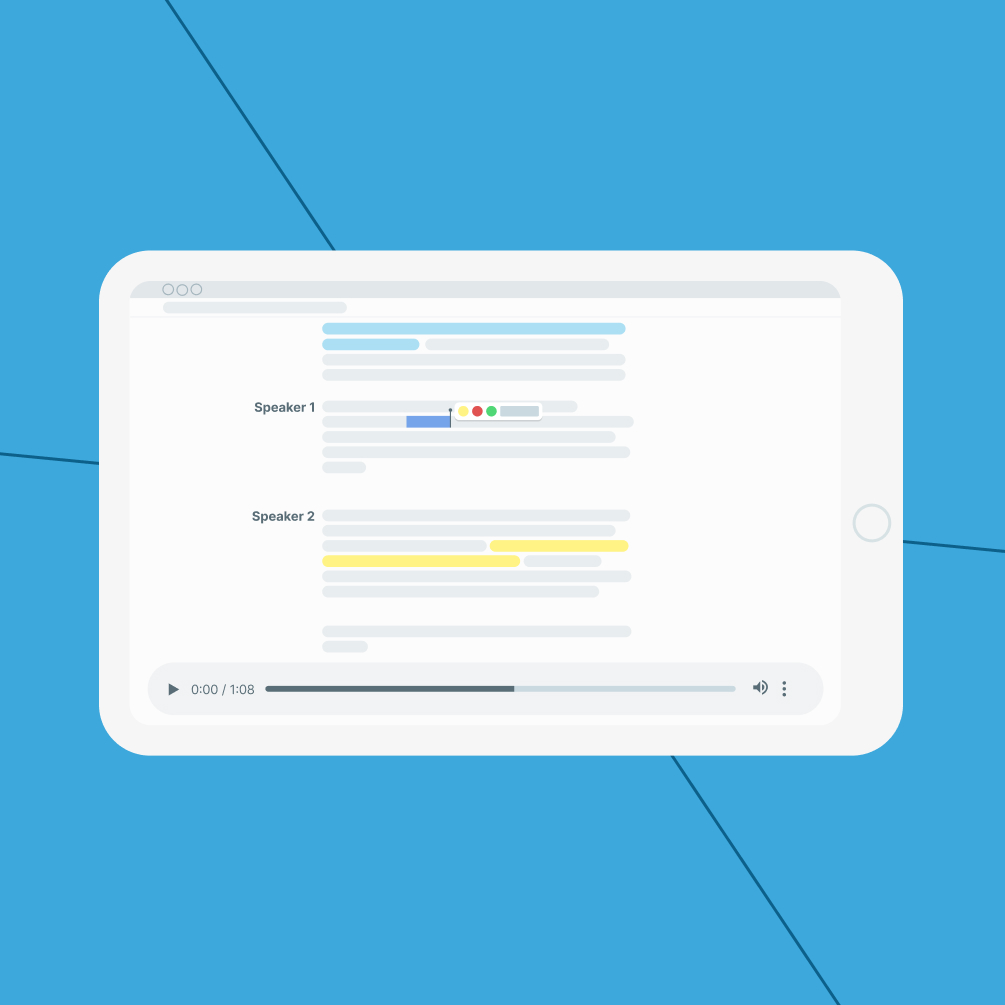
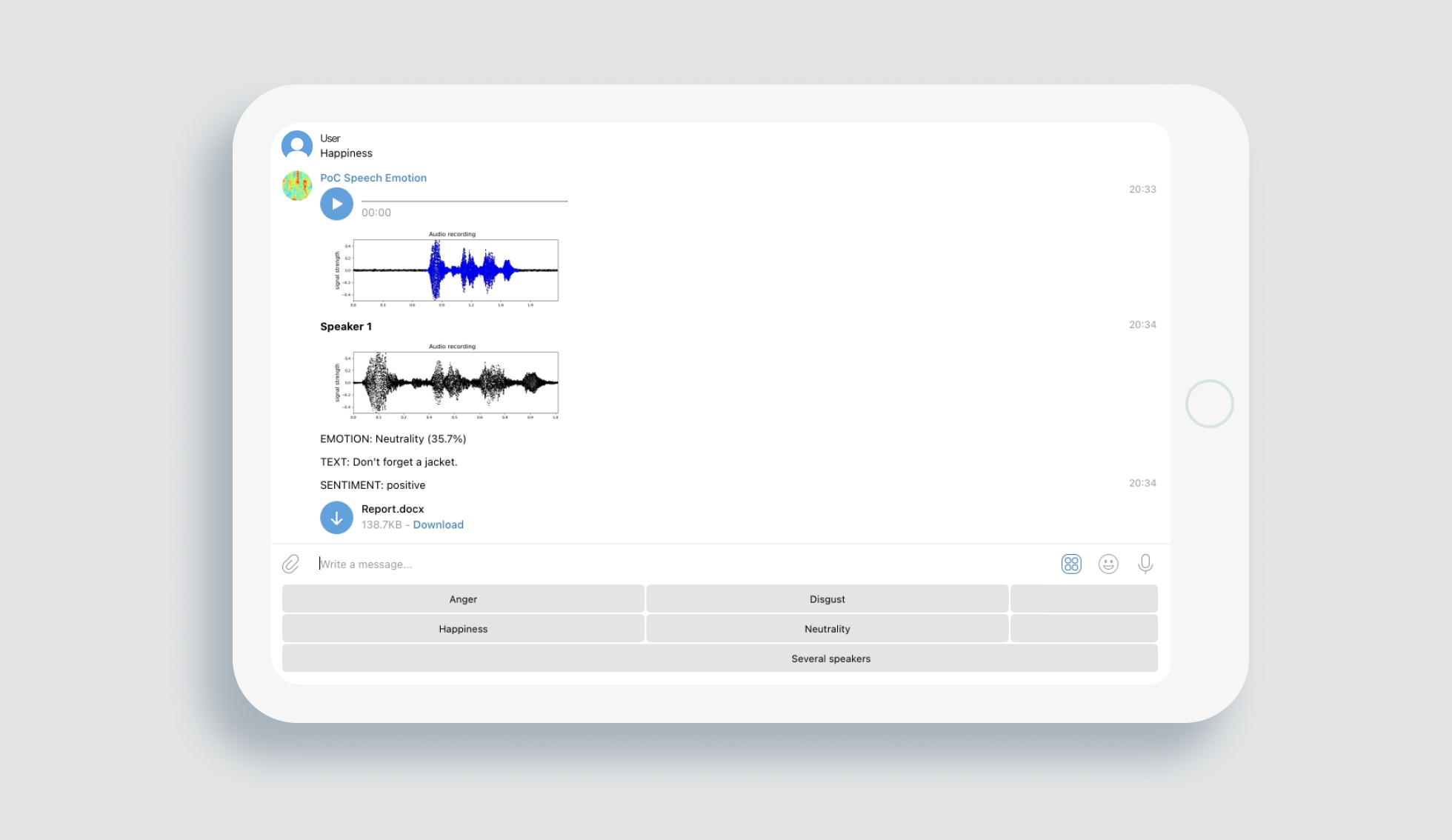
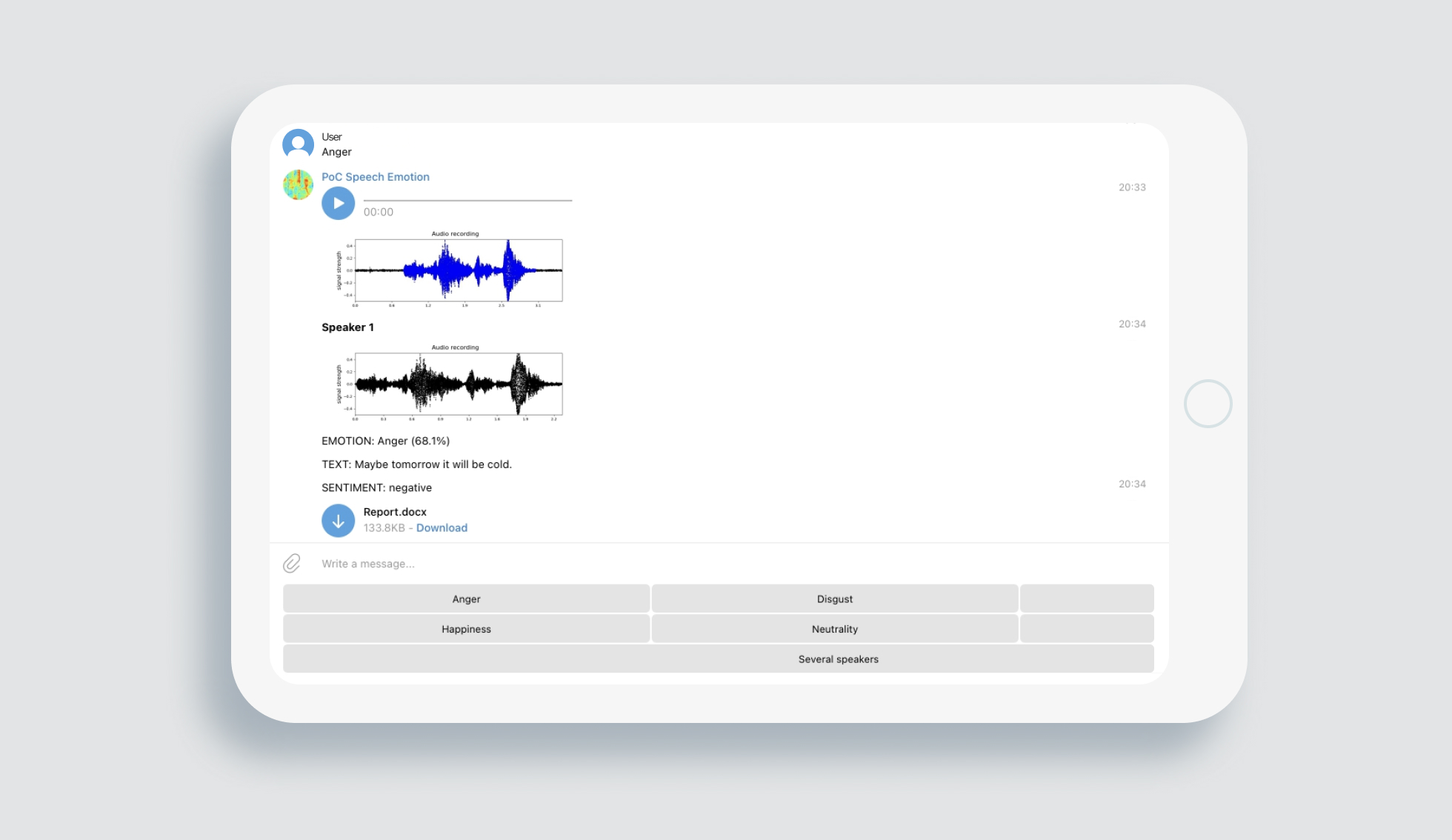
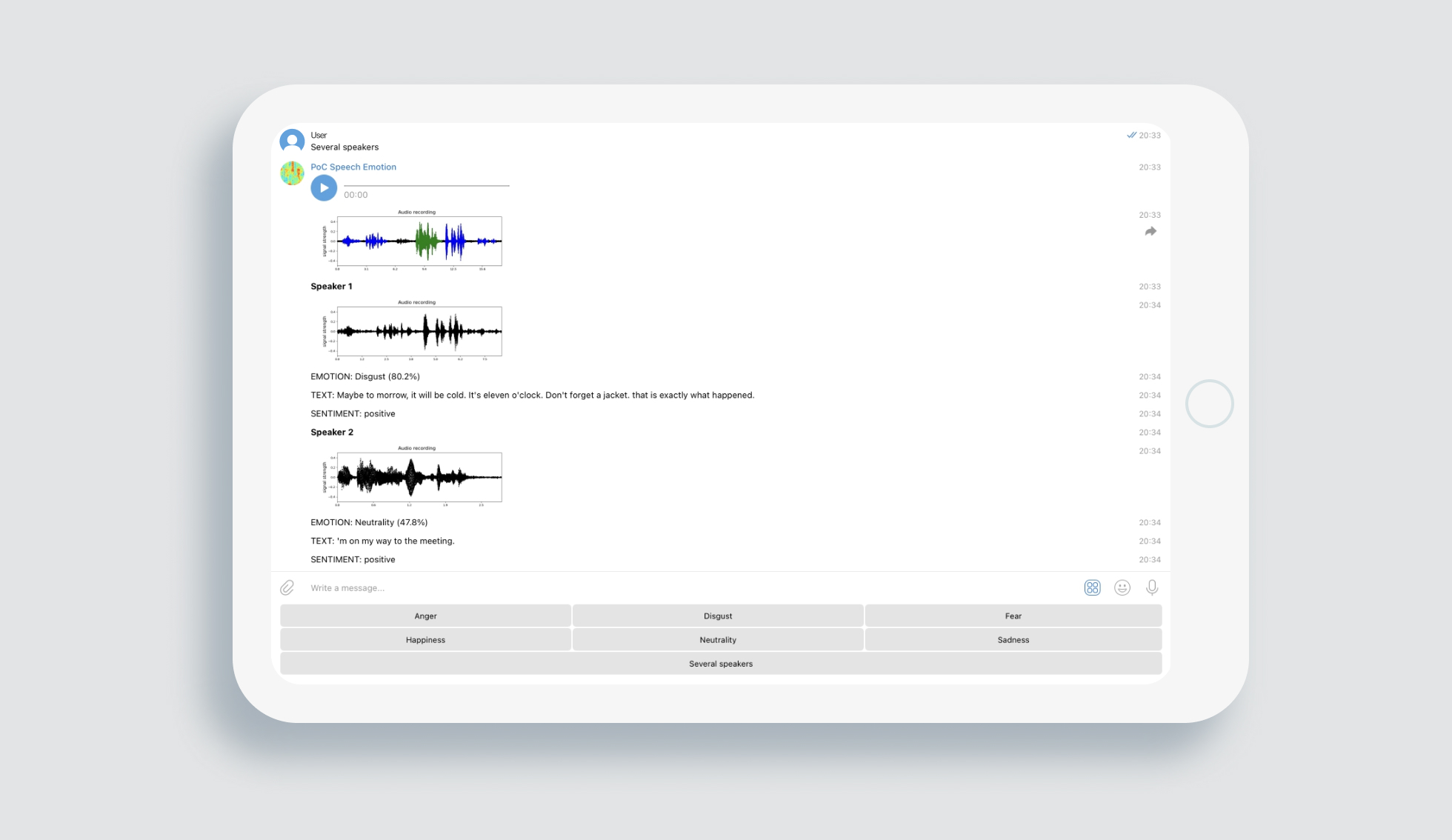
We decided to create a proof-of-concept detecting emotions from speech characteristics for hypothesis testing. It works with users’ audio files, including extracted sound from video files; identifies a speech and builds a spectrogram — a graph representing signal frequency power at a particular time. Then, preprocesses it, and extracts voice features of four types characterizing a timbre of voice, pauses, and other properties of speech.
The voice characteristics are processed using a novel pre-trained AI model to detect six emotions in speech: anger, disgust, fear, happiness, neutrality, and sadness. It gives information on whether there is a dominant emotion and depicts the probability level of top emotions based on 125 speech signal characteristics and preprocessed recordings of people in various emotional states.
To reach the result, we worked according to DIET — an approach to developing Computer Vision solutions with Discover, Ideation, Experiment, and Transformation stages.
Hypothesis research
Discovery
Firstly, at the Discovery stage, we defined the challenge answering the question: what need does our product cover? The main problem was a lack of understanding of what emotions other people feel, and it caused conflicts in relations.
Thus, we determined a way of solving this challenge: the development of emotion detection PoC using a Machine Learning model recognizing them by speech characteristics. It is essential to mention that no software existed on the market was available to solve the described problem, so we focused on scientific literature analysis to create the first one. We carefully examined the scientific publications of international databases Scopus, Web of Science, and PubMed over the past five years related to advanced solutions in this field. During the analysis, we have explored different approaches, including deep neural network solutions: transformers, convolutional neural networks, and traditional digital signal processing solutions. Diving into a challenge, we were able to identify the advantages and disadvantages of each method.
We decided to use Deep Learning for speech text and emotion sentiment analysis and recognition. Also, we defined the system’s operating conditions: minimal requirements for the audio record quality — optimal signal-to-noise ratio allowing us to process a voice, language, audio format, and the number of speakers.
Ideation
At the Ideation stage, we analyzed scientific literature describing approaches to the detection of emotions by voice signals and other physical and physiological indicators. As a result, we defined 4 groups of key features:
- PRAAT features. PRAAT is a software package for formatting and analyzing sound signals; using it we marked the main frequency, pitch, harmonic to noise, jitter, shimmer, intensity, and formants features for our solution.
- MFCC features characterizing voice timbre – a “color” of a tone (librosa package). In our case, we worked with mean, variance, min, max, kurtosis, and skewness for 13 spectral ranges.
- The non-linear model features also describing voice timbre (parselmouth package). Necessary for us were mean, variance, min, max, kurtosis, and skewness for 16 core frequencies.
- Pauses features: the speech and pause time, its number and frequency.
Then, we started the development of a solution and created software obtaining these characteristics from audio recordings of various durations.
Experiment
Here we conducted a big study of models’ hyperparameters on the prepared dataset, the closest to the real situation when the input of the model receives signals recorded on the phone or laptop microphone.
A dataset was prepared based on the CREMA-D dataset with phrases from different people with different emotions mixed into dialogues. It is essential to mention that all the recordings are collected in crowdfunding, where people made recordings in various emotional states on their devices.
As a result of research, we developed a demo product as a Telegram bot ready for implementation into client’s work environment and its Transformation. A significant number of speech characteristics, a high-quality Machine Learning model trained on a dataset with recordings on a phone or laptop microphone with a lоt of speakers and relatively low audio quality allow our software to work not only in ideal laboratory conditions but also in real life.
This way, we’ve got a novel emotion recognition prototyped solution that could help identify signs of psychological disorders in the early stages. Even if a depressed person says everything is okay and they feel fine, our AI bot will reveal a mismatch between words and their actual mental state. In particular, this solution will be helpful in analyses of the psychological state of employees. Therefore, it reduces the number of conflicts and misunderstandings in a company providing businesses with higher efficiency and performance through better communication quality within a team.
AI-based system removing a part of the burden from managers with automated analysis of counterpart emotional state.
A software solution helping to understand customers better and provide a better service.
Team building software contributing to a healthy work environment and the creation of a bonded team.