Computer Vision Audio to Text Converter
AI-powered automated call transcription.
- Service
-
AI Development
Services
- Industry
- IT & Software Services
Challenge
The modern world surrounds us with large amounts of information: daily, we make calls and deal with messengers, social media, and work chats. Usually, during work calls, taking notes is necessary, so recording all arrangements can distract from a conversation. Otherwise, if you use an app that automatically translates voice to text, you can concentrate on the main problem and increase communication efficiency.
Hypothesis
Resolving this challenge, we’ve decided to develop a PoC audio-to-text converter documenting important information from everyday calls, especially work ones. We designed the set of ML models performing the following steps:
- Voice activity detection (VAD) by the standalone model.
- Recognition of speakers — up to 20 people per recording (speakers diarization), and assignment of labels to their speech parts in audio.
- Detection of words and sentences and their assignment to timestamps and speakers.
- Named entity detection — recognition and listing of crucial entities described in the conversation: places, dates, persons, and companies.
- Export of the call transcription as a text file with timestamps, speaker labels, and other important information.
The key process of word detection, punctuation marks and capital letters placement, and identification of speakers is based on audio-to-text Deep Learning neural networks.
During the development process, we used DIET: our step-by-step approach to Computer Vision projects, helping us to deliver workable solutions with significant outcomes for a business.
Hypothesis research
Discovery
At the Discovery stage, we defined a problem. During long ZOOM calls, it is hard to keep focus on the conversation topic, making notes simultaneously. Besides, it complicates the work process and creates an unnecessary burden. As a possible solution hypothesis, we considered the call transcription with the identification of each speaker and convenient text transcripts.
Here we determined the necessary conditions for the system’s prototype to work: minimal requirements for the call quality, recording duration, audio format, and the number of speakers. Also, we evaluated the possibility of using ready-made solutions from big enterprises (NVIDIA, Microsoft, Google, Yandex, Amazon).
Ideation
In the second step, we conducted comparison research and chose some instruments for every stage of voice signal processing: voice activity detection, recognition of speakers, detection of words and sentences, named entity detection, and export of call transcription.
Furthermore, we set up hyperparameters of every neural network and compiled them in a unified solution. For the tests, we prepared a CREMA_D_Diarization database built on an existing CREMA_D database with recordings of speakers in different emotional states mixed in dialogues. As an outcome, we’ve developed a demo product resolving the main task: to make a transcription of calls and provide call members with handy notes.
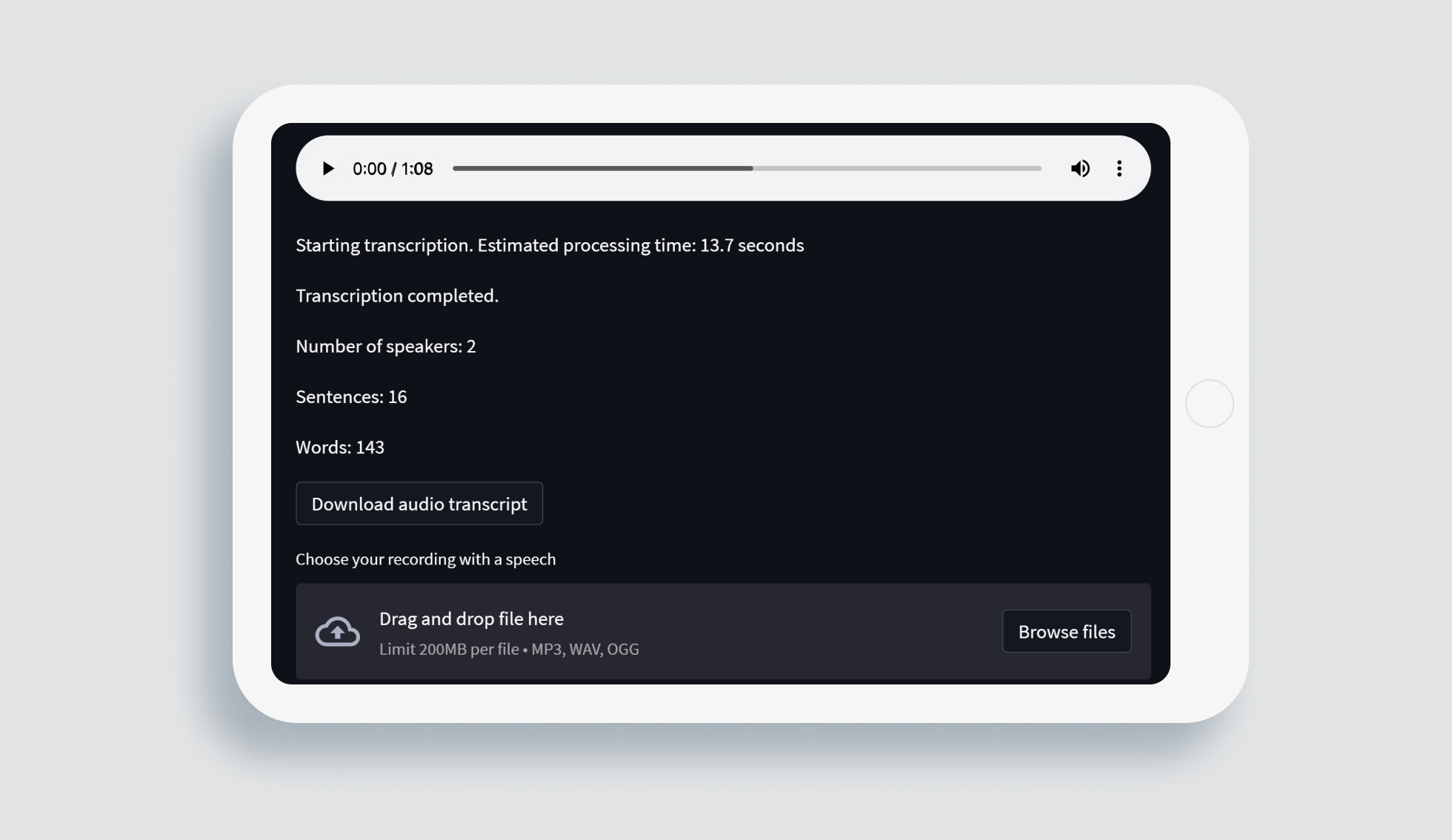
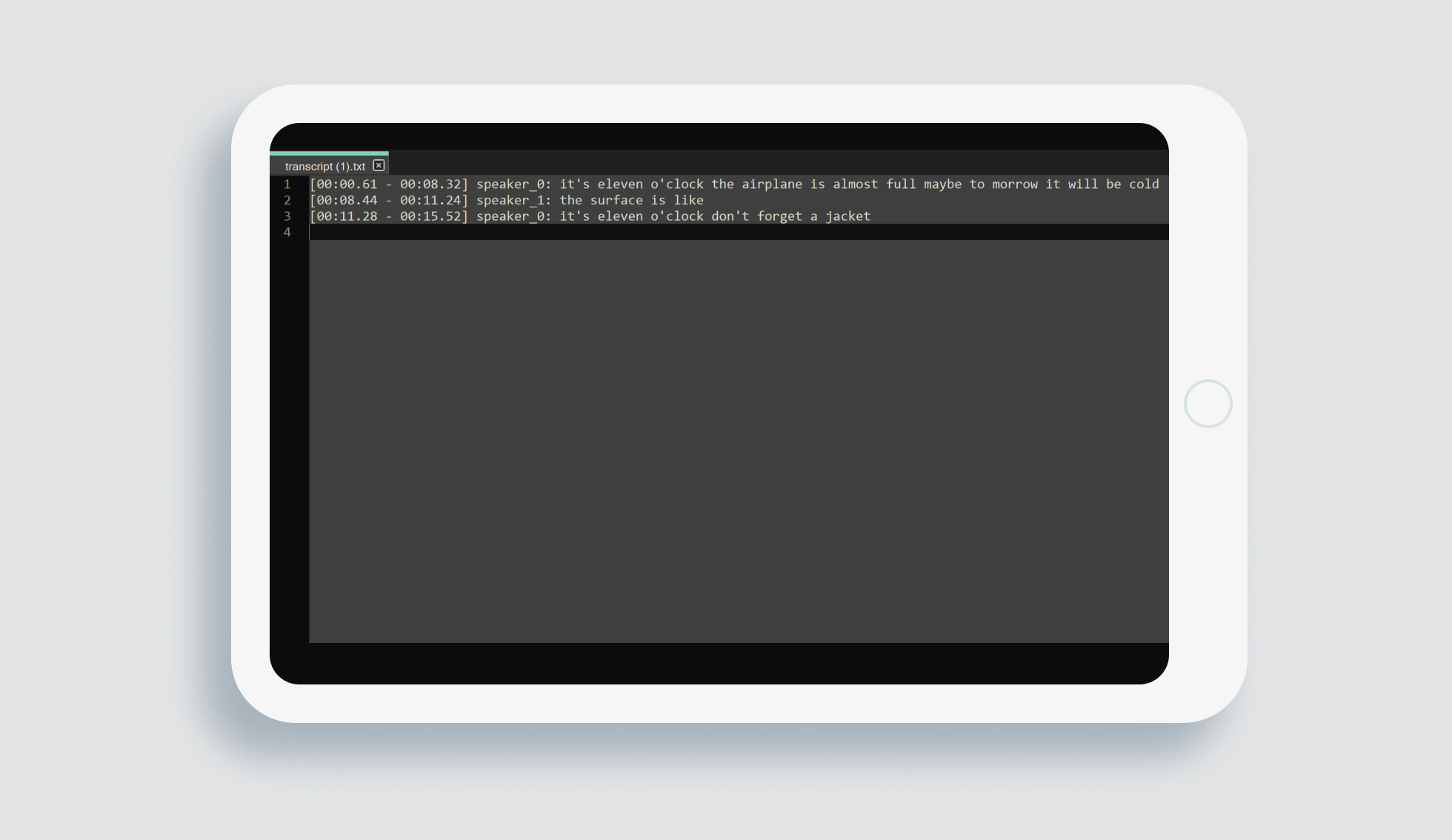
In the next Experiment and Transformation steps, our PoC is ready for a series of experiments to connect metrics and quality of each stage’s functioning, fine-tuning the system’s neural networks, and implementation in a client’s infrastructure.
Using the combination of various neural networks, solving the problem step-by-step, a client gets a high-quality dialogue transcript with up to 20 separate speakers. This audio-to-text Machine Learning solution helps to relieve the burden of remembering all the information people interact with during the day, increases the efficiency of work conversations, and consequently improves the business process.
Automatic call transcription allows for focused conversations, boosting communication efficiency.
Accurate transcription and entity recognition aid in retaining vital details, improving decision-making.
High-quality transcripts for multi-speaker calls reduce cognitive load, optimizing business operations.